Imaginez que vous lancez un dé à six faces et que vous notez le résultat obtenu. Ce résultat est imprévisible avant le lancer, mais il ne peut prendre que six valeurs bien distinctes : 1, 2, 3, 4, 5 ou 6. C’est précisément ce que capte la notion de variable aléatoire discrète : une quantité numérique dont la valeur dépend du hasard, et dont l’ensemble des valeurs possibles est fini ou, au plus, infini mais énumérable un à un. Comprendre cette notion, c’est poser la première pierre de toute la théorie des probabilités — un outil indispensable aussi bien en statistiques, en physique, en informatique qu’en économie.
Ce cours guide pas à pas, depuis la définition rigoureuse jusqu’au calcul de l’espérance et de la variance, en passant par des exemples concrets issus du quotidien. Chaque notation est expliquée dès sa première apparition, et chaque formule est justifiée intuitivement avant d’être démontrée.
Définition d’une variable aléatoire discrète
Avant d’entrer dans le vif du sujet, rappelons le cadre général. En probabilités, on modélise toujours une expérience aléatoire par un espace probabilisé — c’est-à-dire un triplet \( (\Omega,\, \mathcal{A},\, P) \) où :
- \(\Omega\) (lire « oméga ») désigne l’univers, l’ensemble de toutes les issues possibles de l’expérience ;
- \(\mathcal{A}\) est une tribu (ou sigma-algèbre), la famille des événements auxquels on peut attribuer une probabilité ;
- \(P\) est la mesure de probabilité, une fonction qui à chaque événement associe un nombre entre 0 et 1.
Une variable aléatoire est alors simplement une façon de « coder » numériquement les issues de l’expérience. Plus précisément :
Définition : Variable aléatoire discrète
Soit \( (\Omega,\, \mathcal{A},\, P) \) un espace probabilisé. Une variable aléatoire réelle est une application
telle que, pour tout réel \(x\), l’ensemble \(\{X = x\} = \{\omega \in \Omega \mid X(\omega) = x\}\) soit un événement (c’est-à-dire appartienne à \(\mathcal{A}\)).
On dit que \(X\) est discrète lorsque son ensemble image \(X(\Omega)\) est fini ou dénombrable (c’est-à-dire que ses valeurs peuvent être énumérées une par une, même s’il en existe une infinité).
En pratique, cela signifie que \(X\) ne peut prendre qu’une liste (éventuellement longue, mais listable) de valeurs : \(x_1, x_2, x_3, \ldots\) Il peut s’agir d’entiers, de rationnels, ou de n’importe quels réels — l’essentiel est qu’on puisse les compter.
⚠️ Erreur fréquente : On confond souvent « discrète » et « finie ». Une variable aléatoire discrète peut très bien prendre une infinité de valeurs (par exemple \(X(\Omega) = \mathbb{N}\)), à condition que cet ensemble soit dénombrable. L’opposé de « discrète » est « continue » (les valeurs remplissent un intervalle réel), pas « infinie ».
Exemples fondamentaux
- Lancer d’un dé à six faces : \(X\) est le résultat obtenu. \(X(\Omega) = \{1, 2, 3, 4, 5, 6\}\) — variable discrète finie.
- Rang du premier « pile » lors de lancers successifs : ce rang peut valoir 1, 2, 3, … sans limite. \(X(\Omega) = \mathbb{N}^*\) — variable discrète infinie.
- Indicatrice d’un événement \(A\) : \(\mathbf{1}_A(\omega) = 1\) si \(\omega \in A\), et \(0\) sinon. C’est la variable discrète la plus simple — elle ne prend que deux valeurs.
La loi de probabilité d’une variable aléatoire discrète
Une fois la variable \(X\) bien définie, la question centrale est : avec quelle probabilité prend-elle chacune de ses valeurs ? C’est précisément ce que décrit la loi de probabilité.
Définition : Loi de probabilité (distribution)
Soit \(X\) une variable aléatoire discrète à valeurs dans \(X(\Omega) = \{x_1, x_2, \ldots\}\). La loi de probabilité de \(X\) est la donnée de toutes les probabilités
Ces probabilités vérifient nécessairement : \(0 \leq p_i \leq 1\) pour tout \(i\), et
On représente souvent la loi de \(X\) dans un tableau de distribution :
| \(x_i\) | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| \(P(X = x_i)\) | \(\tfrac{1}{6}\) | \(\tfrac{1}{6}\) | \(\tfrac{1}{6}\) | \(\tfrac{1}{6}\) | \(\tfrac{1}{6}\) | \(\tfrac{1}{6}\) |
La somme des probabilités vaut bien \(6 \times \tfrac{1}{6} = 1\). ✓
Fonction de répartition
Un outil complémentaire est la fonction de répartition \(F_X\), définie pour tout réel \(t\) par :
Elle est croissante, en escalier (puisque \(X\) est discrète), et tend vers 0 à \(-\infty\) et vers 1 à \(+\infty\). Chaque « saut » de hauteur \(p_i\) survient à l’abscisse \(x_i\). On calcule facilement : \(P(a < X \leq b) = F_X(b) – F_X(a)\).
Pour aller plus loin sur la construction des espaces probabilisés, consultez notre cours sur les probabilités conditionnelles et la formule de Bayes.
L’espérance mathématique : la « valeur moyenne » d’une variable aléatoire discrète
Connaître la loi de \(X\) est une information complète mais parfois dense. Pour résumer le comportement de \(X\) en un seul nombre, on calcule son espérance mathématique — l’analogue probabiliste de la moyenne.
Définition et théorème : Espérance d’une variable aléatoire discrète
Soit \(X\) une variable aléatoire discrète à valeurs dans \(\{x_1, x_2, \ldots\}\) avec \(P(X = x_i) = p_i\). On dit que \(X\) admet une espérance si la série \(\sum_{i} |x_i|\, p_i\) converge. Dans ce cas, l’espérance mathématique de \(X\) est :
Intuitivement, \(E(X)\) représente la valeur que l’on « espère » obtenir en moyenne si on répétait l’expérience un très grand nombre de fois.
Exemple : Tombola
Un jeu de tombola propose : gagner 100 € avec probabilité \(\tfrac{1}{50}\), gagner 10 € avec probabilité \(\tfrac{1}{10}\), rien sinon. Soit \(X\) le gain en euros :
| \(x_i\) | 0 | 10 | 100 |
|---|---|---|---|
| \(P(X = x_i)\) | \(\tfrac{39}{50}\) | \(\tfrac{1}{10}\) | \(\tfrac{1}{50}\) |
L’espérance est :
Si le billet coûte 3 €, le jeu est dit équitable — en moyenne, on ne gagne ni ne perd.
Propriétés de l’espérance
Soient \(X\) et \(Y\) deux variables aléatoires discrètes d’espérances finies, et \(\lambda \in \mathbb{R}\). Alors :
- Linéarité : \(E(\lambda X + Y) = \lambda\, E(X) + E(Y)\).
- Positivité : si \(X \geq 0\), alors \(E(X) \geq 0\).
- Variable certaine : si \(X = c\) (constante), alors \(E(X) = c\).
- Théorème de transfert : pour toute fonction \(f : \mathbb{R} \to \mathbb{R}\),\[ E(f(X)) = \sum_{i} f(x_i)\, p_i, \]
dès que cette série converge absolument.
⚠️ Erreur fréquente : Le théorème de transfert signifie que \(E(f(X)) \neq f(E(X))\) en général. Par exemple, \(E(X^2) \neq [E(X)]^2\). Cette inégalité est au cœur de la définition de la variance.
Variance et écart type : mesurer la dispersion
L’espérance donne la valeur centrale, mais deux variables peuvent avoir la même espérance tout en se comportant très différemment : l’une concentrée autour de sa moyenne, l’autre très éparpillée. C’est le rôle de la variance de quantifier cet écartement.
Définition : Variance et écart type
Soit \(X\) une variable aléatoire discrète admettant une espérance \(E(X)\). On dit que \(X\) admet une variance si \((X – E(X))^2\) est intégrable. Dans ce cas, la variance de \(X\) est :
L’écart type de \(X\) est \(\sigma(X) = \sqrt{V(X)}\). Il est exprimé dans la même unité que \(X\), ce qui le rend plus directement interprétable.
Formule de König-Huygens
En pratique, on préfère souvent la formule équivalente, plus rapide à calculer :
Lecture : « la variance est l’espérance du carré, moins le carré de l’espérance. »
Propriétés de la variance
- \(V(X) \geq 0\), avec égalité si et seulement si \(X\) est une constante presque sûrement.
- Pour \(a, b \in \mathbb{R}\) : \(V(aX + b) = a^2\, V(X)\) (une constante ajoutée ne change pas la dispersion).
- Si \(X\) et \(Y\) sont indépendantes : \(V(X + Y) = V(X) + V(Y)\).
Exemple : Reprise de la tombola
On a trouvé \(E(X) = 3\). Calculons \(E(X^2)\) :
Donc :
L’écart type de 14 € est bien supérieur à l’espérance de 3 € : les gains sont très dispersés, ce qui est caractéristique des jeux de hasard à gros lots rares.
Comprendre intuitivement : la variable aléatoire comme « compteur du hasard »
Maintenant que les définitions formelles sont posées, prenons un peu de recul pour en saisir l’essence.
Imaginez que vous êtes arbitre d’un tournoi de fléchettes. À chaque lancer, vous notez le score obtenu : 1, 3, 5, 10 points selon la zone touchée. Ce que vous faites, instinctivement, c’est définir une variable aléatoire — vous associez un nombre à chaque résultat possible. La variable aléatoire discrète est exactement ce « traducteur » qui transforme des événements qualitatifs en une grandeur numérique.
L’espérance est la valeur que l’on s’attend à obtenir sur le long terme. Ce n’est pas nécessairement une valeur que la variable peut prendre concrètement : l’espérance du dé équilibré vaut 3,5, alors qu’aucun lancer ne donnera jamais 3,5.
La variance, quant à elle, est une mesure de la « fiabilité » de cette moyenne. Une variance faible signifie que les résultats sont concentrés près de l’espérance ; une variance élevée signifie qu’ils peuvent s’en éloigner beaucoup.
Représentation graphique : diagramme en bâtons et fonction de répartition en escalier
Une variable aléatoire discrète se visualise naturellement grâce à deux graphiques complémentaires.
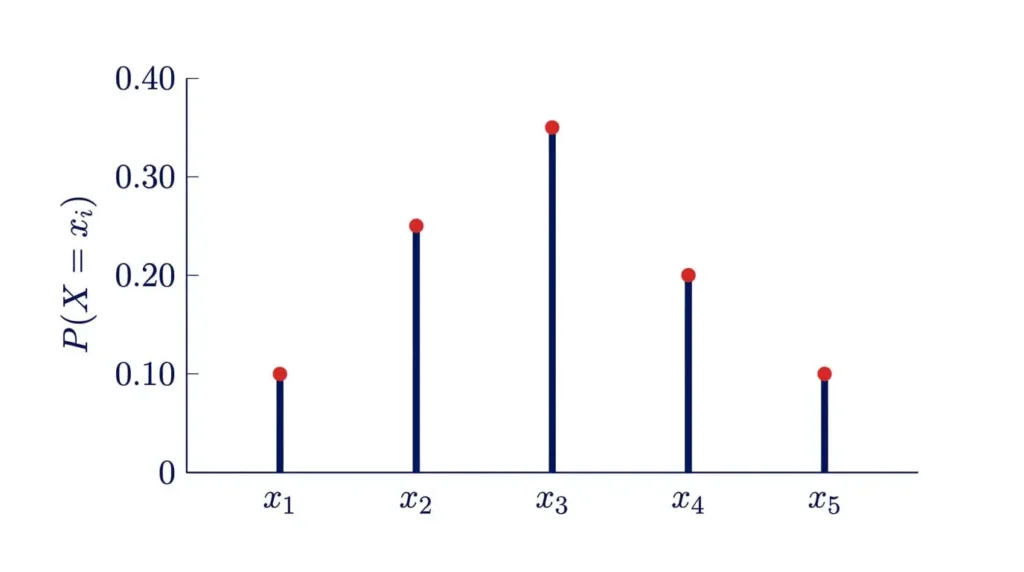
Le diagramme en bâtons représente, pour chaque valeur \(x_i\), un bâton vertical de hauteur \(p_i = P(X = x_i)\). La somme des hauteurs vaut toujours 1.
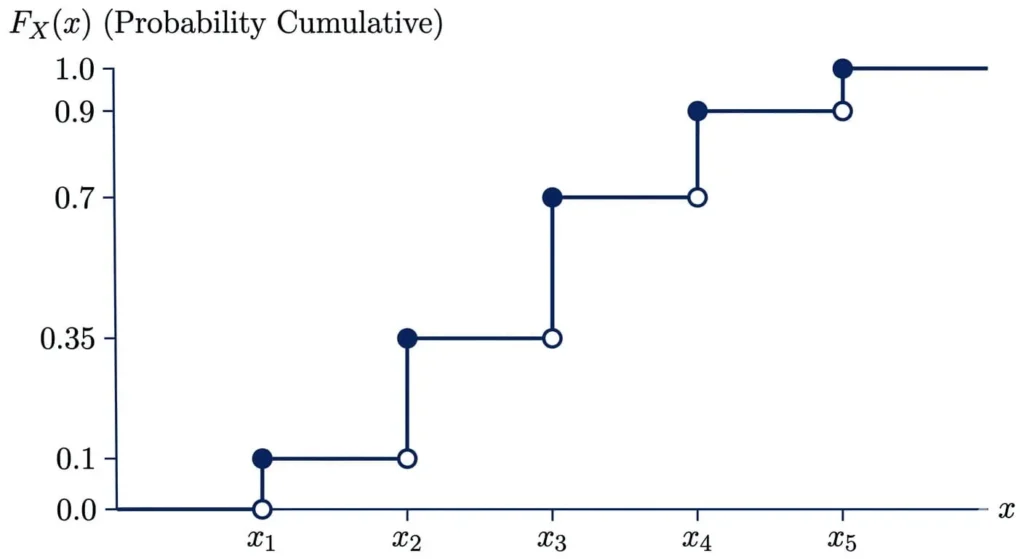
La fonction de répartition en escalier saute d’une hauteur \(p_i\) à chaque valeur \(x_i\). Lire ce graphe permet immédiatement de trouver \(P(X \leq t)\) pour n’importe quel réel \(t\).
Les grandes lois discrètes : loi binomiale et loi de Poisson
Certaines variables aléatoires discrètes reviennent si fréquemment en pratique qu’on leur a donné un nom et calculé une fois pour toutes leur espérance et leur variance.
La loi binomiale \(\mathcal{B}(n, p)\)
On répète \(n\) fois, de façon indépendante, une épreuve de Bernoulli (succès avec probabilité \(p\), échec avec probabilité \(1-p\)). Si \(X\) est le nombre de succès, alors \(X \sim \mathcal{B}(n, p)\) avec :
On a \(E(X) = np\) et \(V(X) = np(1-p)\).
La loi de Poisson \(\mathcal{P}(\lambda)\)
La loi de Poisson de paramètre \(\lambda > 0\) modélise le nombre d’occurrences d’un événement rare dans un intervalle de temps ou d’espace fixé. Si \(X \sim \mathcal{P}(\lambda)\) :
On a \(E(X) = \lambda\) et \(V(X) = \lambda\) — espérance et variance sont égales, propriété remarquable de cette loi.
⚠️ Erreur fréquente : Pour appliquer la loi binomiale, les épreuves doivent être indépendantes et la probabilité de succès constante. Si le tirage est effectué sans remise dans une urne, c’est la loi hypergéométrique qui s’applique, pas la loi binomiale.
Pour une étude complète de la loi binomiale, rendez-vous sur notre cours dédié à la loi binomiale : cours, propriétés et exercices corrigés.
Démonstration : formule de König-Huygens pour la variance
Voyons maintenant pourquoi la formule \(V(X) = E(X^2) – [E(X)]^2\) est vraie. Cette preuve est un excellent exercice de manipulation algébrique de l’espérance.
- Partir de la définition. Posons \(\mu = E(X)\). Par définition :\[ V(X) = E\!\left[(X – \mu)^2\right]. \]
- Développer le carré.\[ (X – \mu)^2 = X^2 – 2\mu X + \mu^2. \]
- Appliquer la linéarité de l’espérance.\[ E\!\left[(X – \mu)^2\right] = E(X^2) – 2\mu\, E(X) + \mu^2. \]
On a utilisé que \(E(\mu^2) = \mu^2\) (constante) et \(E(2\mu X) = 2\mu E(X)\).
- Substituer \(\mu = E(X)\).\[ V(X) = E(X^2) – 2[E(X)]^2 + [E(X)]^2 = E(X^2) – [E(X)]^2. \]
La formule est démontrée. Elle n’est qu’une conséquence directe du développement d’un carré et de la linéarité de l’espérance.
Conclusion
La variable aléatoire discrète est bien plus qu’un outil technique : c’est un langage universel pour décrire et analyser tout phénomène aléatoire dont les issues sont dénombrables. En résumé :
- Une variable aléatoire discrète \(X\) est une application de \(\Omega\) vers \(\mathbb{R}\) dont l’image est un ensemble fini ou dénombrable.
- Sa loi de probabilité est entièrement décrite par les valeurs \(P(X = x_i) = p_i\), avec \(\sum p_i = 1\).
- L’espérance \(E(X) = \sum x_i p_i\) donne la valeur moyenne théorique ; la variance \(V(X) = E(X^2) – [E(X)]^2\) mesure la dispersion autour de cette moyenne.
- Les lois usuelles — loi binomiale et loi de Poisson — sont des modèles prêts à l’emploi pour de nombreuses situations réelles.
Maîtriser la variable aléatoire discrète ouvre la porte à des concepts plus avancés : les chaînes de Markov, la théorie de l’information, les tests statistiques. Continuez votre parcours avec nos cours sur la loi binomiale et ses applications.
Référence externe : Pour une présentation rigoureuse et complémentaire, consultez l’article Variable aléatoire discrète sur Wikipédia.
Questions fréquentes sur la variable aléatoire discrète
Quelle est la différence entre une variable aléatoire discrète et continue ?
Une variable aléatoire discrète ne peut prendre qu’un ensemble fini ou dénombrable de valeurs (par exemple des entiers). Une variable aléatoire continue prend ses valeurs dans un intervalle réel — comme la taille ou la durée de vie d’un composant. Elle est décrite par une densité de probabilité et non par des probabilités ponctuelles. En pratique : si l’on peut compter les valeurs possibles, la variable est discrète ; si elles remplissent un intervalle, elle est continue.
Comment calculer l’espérance d’une variable aléatoire discrète ?
On multiplie chaque valeur possible \(x_i\) par sa probabilité \(P(X = x_i)\), puis on additionne tous ces produits : \(E(X) = \sum_{i} x_i \cdot P(X = x_i)\). Si la variable suit une loi usuelle, on applique directement les formules connues : \(E(X) = np\) pour une loi \(\mathcal{B}(n,p)\), et \(E(X) = \lambda\) pour une loi \(\mathcal{P}(\lambda)\).
Qu’est-ce que la loi de probabilité d’une variable aléatoire discrète ?
La loi de probabilité de \(X\) est la donnée complète de toutes les probabilités \(P(X = x_i)\) pour chaque valeur \(x_i\) que peut prendre \(X\). Elle doit satisfaire deux conditions : chaque probabilité est entre 0 et 1, et leur somme vaut exactement 1. Connaître la loi de \(X\), c’est connaître tout ce qu’il y a à savoir sur son comportement probabiliste.
Comment démontrer qu’une variable aléatoire est discrète ?
Il suffit de montrer que l’ensemble image \(X(\Omega)\) est fini ou dénombrable (en bijection avec une partie de \(\mathbb{N}\)). Par exemple : si \(X\) compte le nombre de succès dans une série d’épreuves, \(X(\Omega) \subseteq \mathbb{N}\) — donc \(X\) est discrète. Si \(X\) peut prendre toutes les valeurs d’un intervalle \([a, b]\), elle n’est pas discrète.